はじめに
2022年4月現在、Googleスプレッドシートでは実現可能でEXCELでは実現が難しいことの一つに、正規表現による検索がある。
EXCELでもVBAなどの外部関数を利用すれば正規表現を使えるのだが、標準の関数では正規表現を使えないためハードルが高くなっている。
一方、Googleスプレッドシートでは、標準の関数で正規表現が使えるようになっている。
Googleスプレッドシートで用意されている正規表現用の関数は、以下の4通りだ。
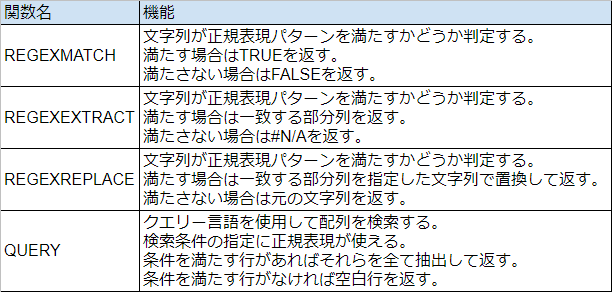
これらのうち、最初の3つの関数は文字列に対して正規表現パターンを検査するものだ。
4つ目の QUERY 関数はやや毛色が異なっていて、配列の探索を行う関数となっている。
探索に際して正規表現も使用できるというものだ。
このような事情もあって、今回の記事では主に最初の3つの関数を詳しく取り上げることにする。
これらの3つの関数は、まさに正規表現による検索を行う関数だからだ。
REGEXMATCH 関数
REGEXMATCH 関数は、文字列が正規表現パターンを満たすか否かの判定を行う関数だ。
もっとも基本的な正規表現の機能だと言えるだろう。
REGEXMATCH 関数の仕様は以下の通りだ。
REGEXMATCH(対象の文字列, 正規表現)
以下に例をあげよう。
文字列中に郵便番号が含まれているか否かを判定する正規表現パターンだ。
なお、郵便番号は、3桁の数字と4桁の数字をハイフンで連結した形式とする。
上記の仕様を満たす式は以下の通りとなる。
=REGEXMATCH(対象の文字列, ".*[0-9]{3}-[0-9]{4}.*")
これをスプレッドシート上で試した結果が以下だ。
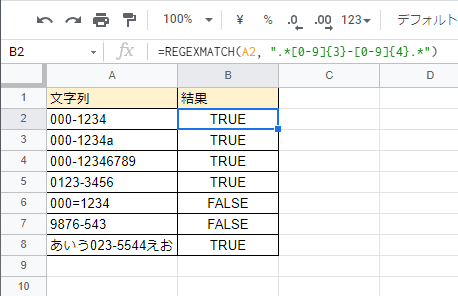
A列の文字列を、B列に設定した式によって条件を満たすか否かの判定をしている。
文字列中に郵便番号のパターンを含む場合に、判定結果が TRUE となっている。
6行目と7行目が FALSE になっているが、6行目は区切り文字がハイフンでなくイコールになっているから条件を満たさず、7行目はハイフンに続く数字列が3文字しかないので条件を満たしていない。
残りの行は全て郵便番号のパターンを文字列中に含んでいるため TRUE となっている。
REGEXEXTRACT 関数
REGEXEXTRACT 関数は、文字列が正規表現パターンを満たすか否かの判定を行い、TRUE の場合に合致した部分列を返す関数だ。
非常に便利な関数なので、一度使い始めたら止められなくなること請け合いの関数だ。
FALSE の場合には #N/A が返って来るので工夫が必要になる場合はあるが、それを補って余りある有用性がある。
REGEXEXTRACT 関数の仕様は以下の通りだ。
REGEXEXTRACT(対象の文字列, 正規表現)
以下に使用例として、文字列中に郵便番号があれば抽出する式を作ってみよう。
REGEXMATCH 関数の時と同様に、郵便番号は3桁の数字と4桁の数字をハイフンで連結した形式とする。
上記の仕様を満たす式は以下の通りだ。
=REGEXEXTRACT(対象の文字列, "[0-9]{3}-[0-9]{4}")
これをスプレッドシート上で試した結果は以下の通りだ。
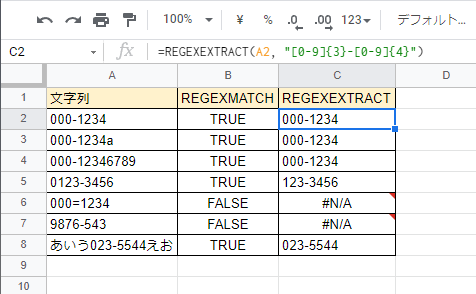
A列の文字列から、C列に設定した式によって、郵便番号が含まれている場合にそれを抽出している。
郵便番号が含まれていない場合は、#N/A値を表示している。
余談にはなるが、REGEXMATCH 関数がどの部分を TRUE と判定したのかは、当関数の抽出結果を見れば分かるようになっている。
REGEXREPLACE 関数
REGEXREPLACE 関数は、文字列が正規表現パターンを満たすか否かの判定を行い、TRUE の場合に合致した部分列を置換用の文字列で置き換えて返す関数だ。
FALSE の場合には元の文字列をそのまま返すようになっている。
REGEXREPLACE 関数の仕様は以下の通りだ。
REGEXREPLACE(対象の文字列, 正規表現, 置換文字列)
使用例を以下に示そう。
これまで使用したサンプルを一部改変し、文字列中に郵便番号があれば、それをアスタリスク(*)で置換して読めないようにする式を作ってみよう。
郵便番号の形式は、REGEXMATCH 関数や REGEXEXTRACT 関数の時と同様に、3桁の数字と4桁の数字をハイフンで連結した形とする。
上記の仕様を満たす式は以下の通りとなる。
=REGEXREPLACE(対象の文字列, "[0-9]{3}-[0-9]{4}", "***-****")
これをスプレッドシート上で試した結果は以下の通りだ。
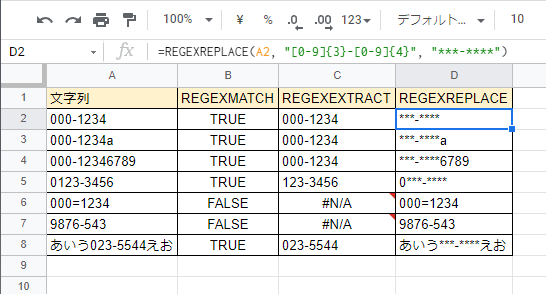
A列の文字列から、D列に設定した式によって、郵便番号が含まれている場合にそれを「****-***」で置換している。
郵便番号が含まれていない場合は、元の文字列をそのまま表示している。
他の処理系の正規表現との違い
この項ではGoogleスプレッドシートの正規表現の仕様と、他の一般的な処理系との違いについて紹介する。
Googleスプレッドシートで使える正規表現は、JavaやPHPなどの高級言語で使える正規表現に比べると、機能的にやや見劣りするものとなっている。
Googleスプレッドシートでは「RE2 正規表現」という正規表現ライブラリーを使用しているようだ。
RE2 の仕様は以下のURLで公開されているので、確認しておくと良いだろう。
https://github.com/google/re2/blob/main/doc/syntax.txt
RE2 は高速かつメモリー使用量が少ないという特徴を持つようだが、その反面いくつかの機能が未実装となっている。
具体的には、上記のリンク先で「NOT SUPPORTED」になっている機能は全て実装されていないようだ。
意外にもかなりたくさんあるので驚いてしまう。
この中で使用頻度が高いのは前方参照だろうか。
マッチした文字列を再利用する機能で、文中では「\1」と表記されているが、他の処理系では「\n」などと表記されることが多い機能だ。
他には強欲な数量子などと呼ばれる「x++」と表記されるパターンも使えないようだ。
実装されていない機能はそれなりに多いので、ニーズにマッチしないケースがあることを考慮する必要がある。
ある程度高機能な正規表現パターンを使う場合には、事前に Googleスプレッドシートでのサポート状況を確認しておいた方が良さそうだ。
まとめ
Googleスプレッドシートの正規表現のうち、REGEXMATCH、REGEXEXTRACT、REGEXREPLACE の3つの関数を使用例をまじえて紹介した。
また、Googleスプレッドシートの正規表現の仕様についても紹介した。
一般的な処理系に比べると、やや低機能なサブセットとなっているため、仕様に際しては注意が必要だ。